Datenextraktion
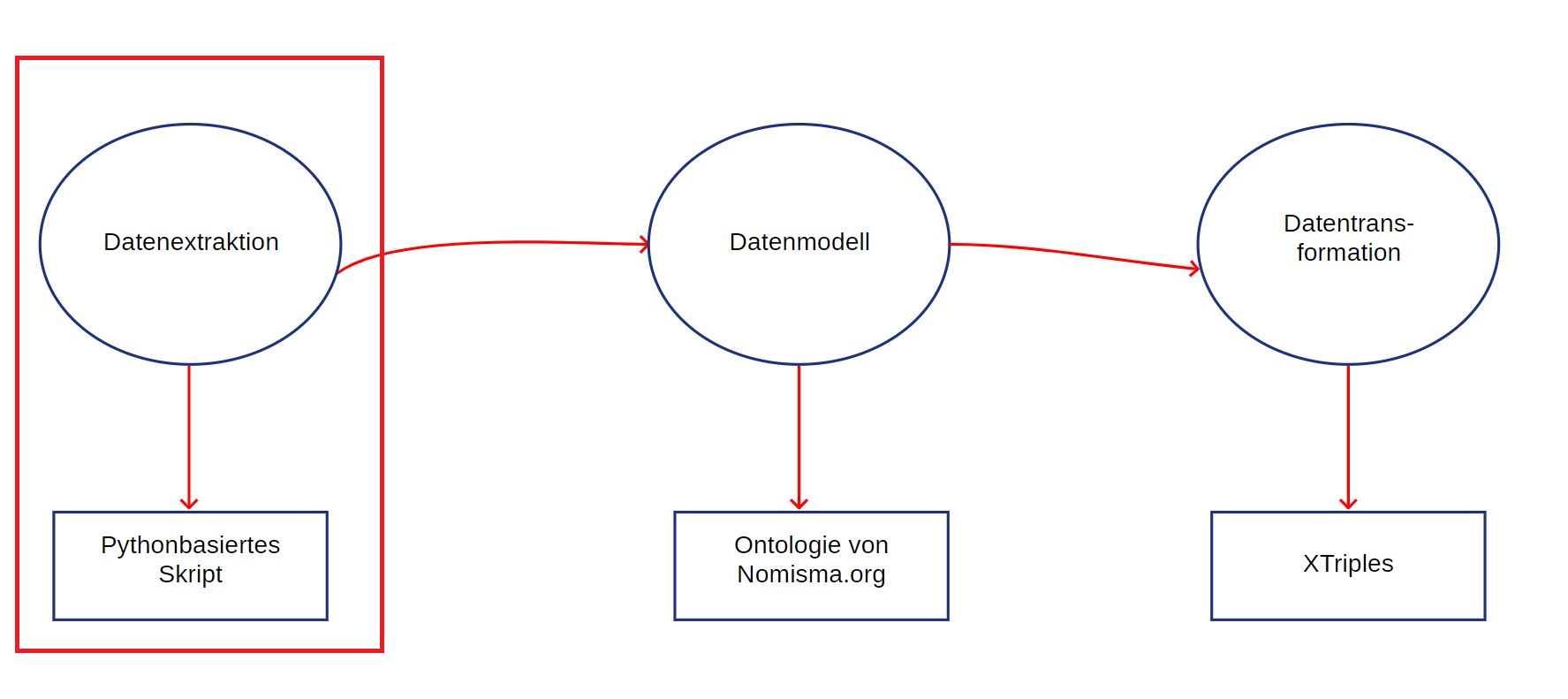
Für die Datenextraktion wurden diverse Open Source Angebote im Internet recherchiert und erprobt. Ziel war es, die tabellarische Struktur eines FMRD-Fundmünzkomplexes zu erkennen und korrekt auszugeben. Das Endformat ist dabei CSV, wobei auch Zwischenformate wie XML erlaubt sind. Es stellte sich jedoch heraus, dass momentan keine Open Source Lösung die FMRD-Daten korrekt extrahieren kann. Gründe dafür sind, dass keine Trennlinien für die Spalten vorhanden sind und die Spalten im ursprünglichen Worddokument mit Tabstopps getrennt waren, die Spalten oder Zeilen ineinander übergehen und die stark heterogenen Münzdaten kein einfaches schematisches Erfassen ermöglichen.
Ein Großteil der getesteten Software nutzte zur Datenbereinigung reguläre Ausdrücke. Mit einer Handvoll regulärer Ausdrücke ist es jedoch nicht möglich, die sehr heterogene Struktur der FMRD-Münzdaten zu erfassen. So wurde ein eigenes Skript entwickelt, welches mit einer Vielzahl von regulären Ausdrücken es ermöglicht, einen Fundmünzkomplex fast vollständig korrekt zu wiederzugeben. Die Münzkomplexe unterscheiden sich jedoch in leichten Details von Band zu Band und auch von Komplex zu Komplex. Diese neuen Varianten können dann ausblickend mit neuen regulären Ausdrücken abgefangen werden. Somit lernt das Skript quasi immer dazu. Die verwendete Skriptsparache ist Python. Für Python wurden bereits eine Vielzahl von nützlichen Bibliotheken entwickelt, die es ermöglichen, schrittweise die Daten aus einem PDF zu extrahieren. Das Ziel ist es dann alle Skripte von der Datenextraktion bis hin zur Datentransformation in einer Pipeline nacheinander ablaufen zu lassen und so vom PDF bis zum fertigen RDF zu gelangen.
Als Entwicklungsumgebung wurde Jupyter Notebook gewählt. Sowohl Jupyter Notebook als auch Python 3 wurden über Anaconda installiert. Im Folgenden wird schrittweise beschrieben, wie sich die Pipeline aufbaut und wie sie zu bedienen ist. Als erstes wird das Skript 1_Seiten_splitten.ipynb in Jupyter Notebook geöffnet und ausgeführt.
Die Pythonbibliothek PyPDF2 wurde importiert um das Dokument aufzuteilen, sodass nur der Beispielfundmünzkomplex als separiertes PDF übrig bleibt. Zunächst wird das PDF mit dem kompletten Fundmünzband eingelesen. Als Output wird muenzkomplex_Split.pdf definiert. Nun müssen die Seiten im PDF angegeben werden, die den Münzkomplex wiederspiegeln. Zu beachten ist hierbei jedoch, dass die Seiten von PyPDF2 als Array eingelesen werden und die Zählung mit 0 bzw. -1 beginnt. Als nächster Schritt wird das Skript 2_PDF_zu_Text.ipynb geöffnet.
Dieses Skript nimmt den Output aus dem vorherigen Schritt und konvertiert mit der Pythonbibliothek tika-python das PDF zu einer Textdatei mit dem Output text_Output.txt.
Der Output der Textdatei wird nun im nächsten Schritt verwendet um die Tabellendaten vom Anmerkungsapparat und weiteren Textelementen zu lösen. Hierfür wird das Skript 3_Text_Bereinigung.ipynb geöffnet. Dieses arbeitet überwiegend mit regulären Ausdrücken, um die reinen Tabellendaten zu gewinnen. Als Output werden hier die Anmerkungen als anmerkungen.csv und die tabellarischen Münzdaten als output_ohne_Kopf_und_Anm.txt ausgegeben.
Die bisherigen Schritte waren alle nötig, um die eigentliche Bereinigung der extrahierten Daten vorzunehmen. Im nächsten Schritt wird das Skript 4_RegEx.ipynb geöffnet und die Textdatei output_ohne_Kopf_und_Anm.txt eingelesen. Das Skript baut auf einer Vielzahl von regulären Ausdrücken auf. Die ersten Schritte entfernen dabei überflüssige Elemente, die bei der Extraktion aus dem PDF entstanden sind, wie die Angabe der Seitenzahlen. Dann folgt das spaltenweise Zuordnen der Münzdaten. Die Spalten werden mit Pipes voneinander getrennt und anschließend als muenzdaten.csv gespeichert.
Da die FMRD-Daten ursprünglich nur durch Tabstopps getrennt waren, sind Angaben die über mehrere Zeilen laufen leider nicht gut extrahierbar. Selbst mit regulären Ausdrücken sind diese nicht klar zu fassen, da die Daten die über mehrere
Zeilen hinweg angegeben wurden bei einer Extraktion durcheinander kommen. Diese Fälle sind manuell zu prüfen und gegebenenfalls zu korrigieren. Im Beispieldatensatz war dies der Fall. Es liegt hier ein Fehlerquotient von 2,85 % vor, was 33
fehlerhaften Zeilen entspricht. Daher wird im folgenden Schritt die Datei muenzdaten_manuell.csv eingelesen, die anzeigt, dass manuelle Korrekturen vorgenommen wurden. Wenn bei anderen Komplexen keine manuellen Korrekturen vorliegen,
kann der Zusatz „manuell“ weggelassen werden und die Pipeline kann einfach durchlaufen. Im folgenden Skript werden die Daten mit der Bibliothek Pandas bearbeitet. Pandas ist speziell darauf
ausgelegt, tabellarische Daten zu bearbeiten. So ist es z. B. möglich die Angabe des Prägeherren bzw. Kaisers statt als Überschrift in einer separaten Spalte zu erfassen. In diesem Schritt wird zudem für jede Fundmünze eine eigene ID
angelegt. Hierfür wird zunächst eine neue Spalte namens Original erzeugt. Im FMRD-Projekt wurde bei der Erfassung der Fundmünzen beachtet, ob diese dem Bearbeiter im Original vorlag oder die Münze z. B. nur noch in archäologischer
Forschungsliteratur zu finden ist. Wenn eine Münze dem Bearbeiter als Original vorlag, wurde bei der Münznummer ein Stern vorangesetzt. Diese Information wurde nun von der Münznummer separiert und in die Spalte Original übertragen. Dort
wird für einen Stern eine 1 und für keinen Stern eine 0 eingetragen. Somit ist mit einem binären Verfahren gekennzeichnet, ob die Münze als Original vorlag oder nicht. Als nächstes wird der Stern sowie der Punkt am Ende der Münznummer
entfernt, sodass nur ein reiner Integer-Wert zurückbleibt. Dieser Wert wird mit der Pythonfunktion zfill() auf einheitliche fünf Stellen gebracht, indem die fehlenden Stellen von vorne mit Nullen gefüllt werden. Dieser Zahl wird der
Rest der ID vorangesetzt. So bedeutet z. B. die ID FMRD-04-03-02-3006-01-00001, dass es sich um den FMRD Band IV (also Rheinland-Pfalz) 3/2 (3 entspricht dem Regierungsbezirk Trier und 2 dem zweiten Band aus der Trierer Reihe) mit dem
Fundkomplex 3006,1 (3006 steht für den Komplex der Trierer Domgrabung und 1 für die Einzelfunde) und der Fundmünze 1 handelt:
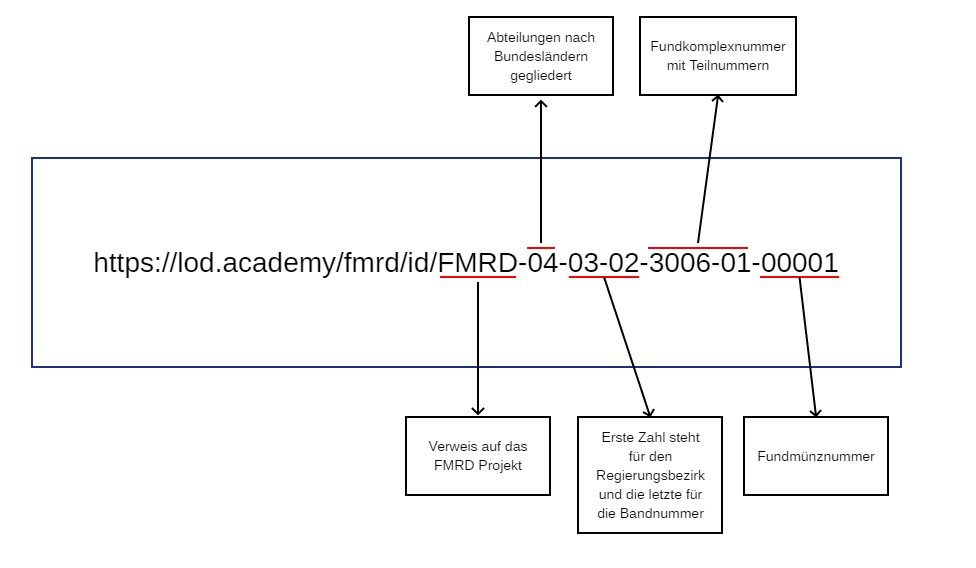 Die ID ist somit identisch zur empfohlenen Zitierweise des FMRD-Projektes aufgebaut. Auf diese Weise ist es möglich, allen Fundmünzen des FMRD-Projektes eine eigene feste ID zu geben.
Ausgegeben werden die bearbeiteten Münzdaten dann als muenzdaten_bearbeitet.csv.
Die ID ist somit identisch zur empfohlenen Zitierweise des FMRD-Projektes aufgebaut. Auf diese Weise ist es möglich, allen Fundmünzen des FMRD-Projektes eine eigene feste ID zu geben.
Ausgegeben werden die bearbeiteten Münzdaten dann als muenzdaten_bearbeitet.csv.
Beim letzen Skript der Datenextraktion muss auch wieder auf eine manuelle Bearbeitung des vorhergehenden Outputs hingewiesen werden. Beim Skript 6_Anmerkungen_einfuegen.ipynb wird zunächst die Datei muenzdaten_bearbeitet_manuell.csv eingelesen. Auch bei dieser manuellen Bearbeitung sind zeilenübergreifende Münzangaben der ausschlaggebende Grund. So sind in einem Fall die Angaben zum Prägeherren über mehrere Zeilen erfasst worden. Dies wurde manuell korrigiert. Als nächstes werden die Anmerkungen, die sich im PDF unterhalb der tabellarischen Münzdaten befanden und extra als CSV separiert wurden, als anmerkungen.csv eingelesen. Die Anmerkungen werden nun mit Pandas als weitere Spalte der Tabelle der Münzdaten hinzugefügt. Leere Zellen und Zellen, die nur Leerzeichen enthalten, werden dann noch als NaN gefüllt. Das Ergebnis wird als muenzdaten_mit_Anm_und_NaN.csv ausgegeben.
Der letzte Output wird bei der Datentransformation wieder aufgegriffen. Doch zunächst wird für die Datentransformation ein Datenmodell benötigt.